
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Presentaion |
|
|
|
|
|
|
|
|
|
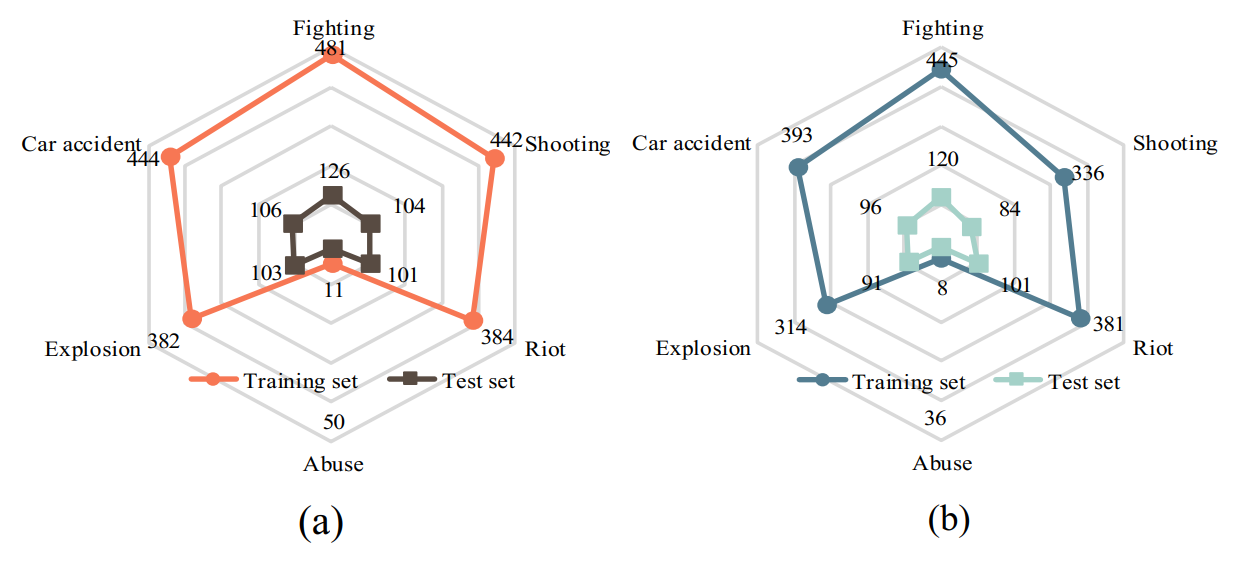 |
| Dataset Statistics. (a) Distribution of the number of videos belonging to each category according to multi-label. (b) Distribution of the number of videos belonging to each category according to the first label. |
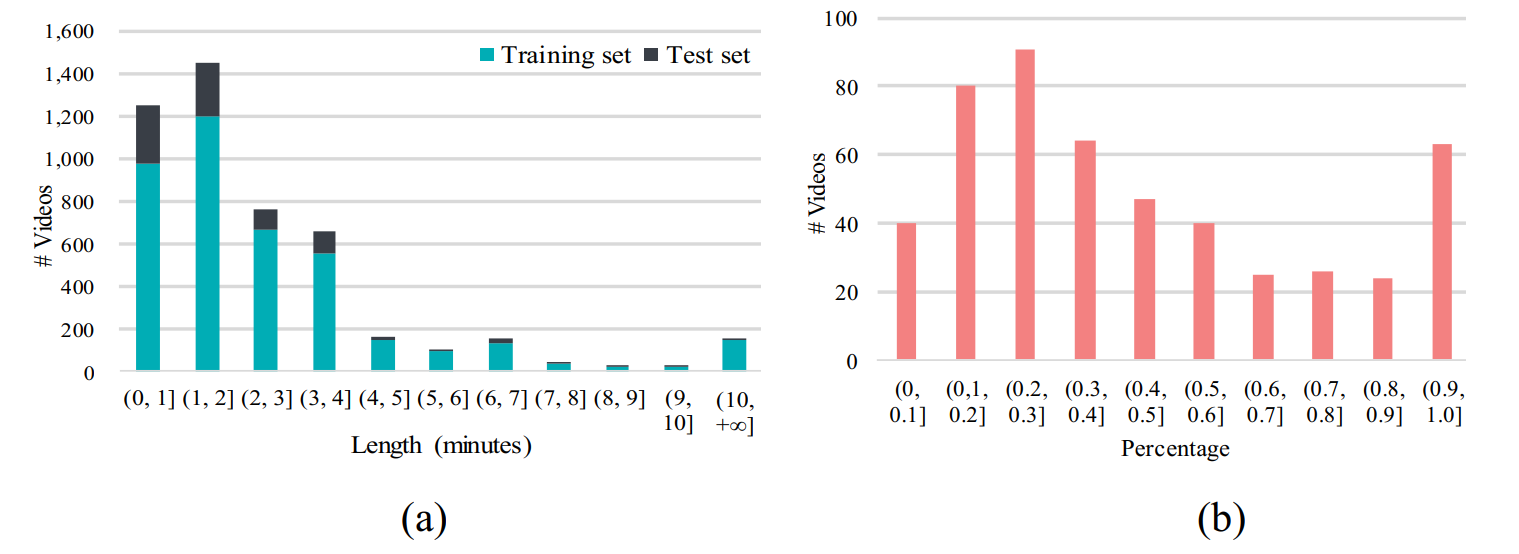 |
| Dataset Statistics. (a) Distribution of videos according to length (minutes). (b) Distribution of violent videos according to percentage of violence (in each video) in test set. |
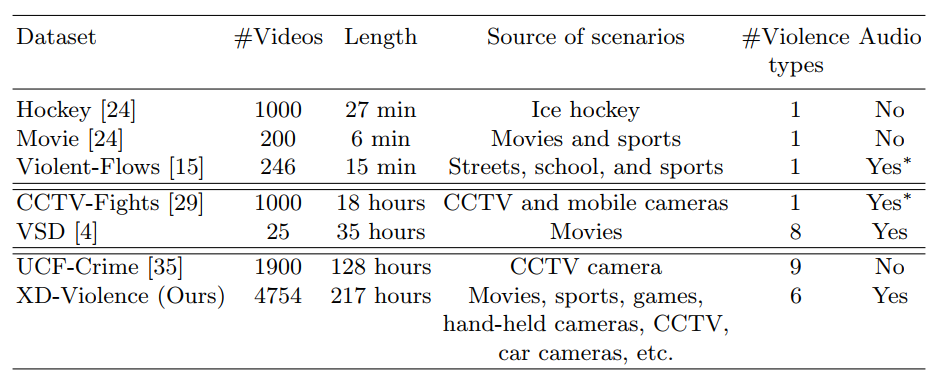 |
| Comparisons of different violence datasets. ∗ means quite a few videos are silent or only contain background music. |
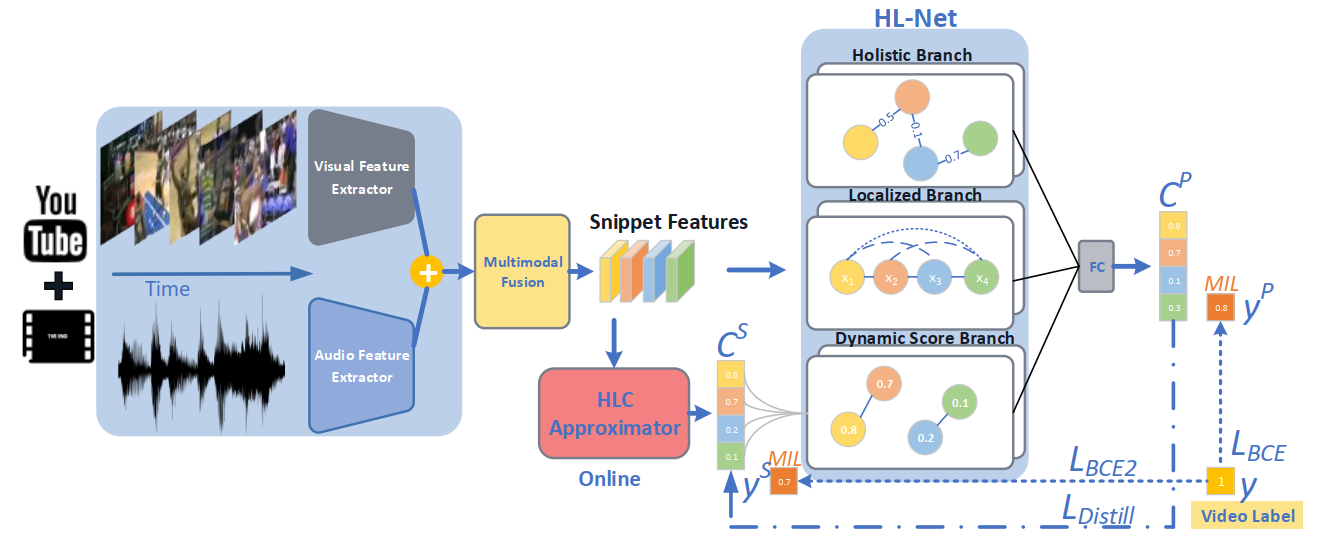 |
| The pipeline of our proposed method. |
|
V1.0 Videos Baidu Netdisk Test Videos [keyword:exye] Test Annotations ReadMe AliyunDrive Training Videos OneDrive Trainging Videos_0001-1004 Trainging Videos_1005-2004 Trainging Videos_2005-2804 Trainging Videos_2805-3319 Trainging Videos_3320-3954 Test Videos Test Annotations V1.0 Features Baidu Netdisk audio features (VGGish) [keyword:i9h2] visual features (I3D RGB&Flow) [keyword:ou1n] ReadMe OneDrive audio features (VGGish) visual features (I3D RGB&Flow) V1.0 PRC Data precision and recall values of PRC |
 |
Peng Wu et al. Not only Look, but also Listen: Learning Multimodal Violence Detection under Weak Supervision In ECCV, 2020. (Paper) |
 |
(Supplementary materials)
|
@inproceedings{Wu2020not,
title={Not only Look, but also Listen: Learning Multimodal Violence Detection under
Weak Supervision},
author={Wu, Peng and Liu, jing and Shi, Yujia and Sun, Yujia and Shao, Fangtao
and Wu, Zhaoyang and Yang, Zhiwei},
booktitle={European Conference on Computer Vision (ECCV)},
year={2020}
}
Acknowledgements |
Contact |